Accepting 2 Pilot Partners for Q1
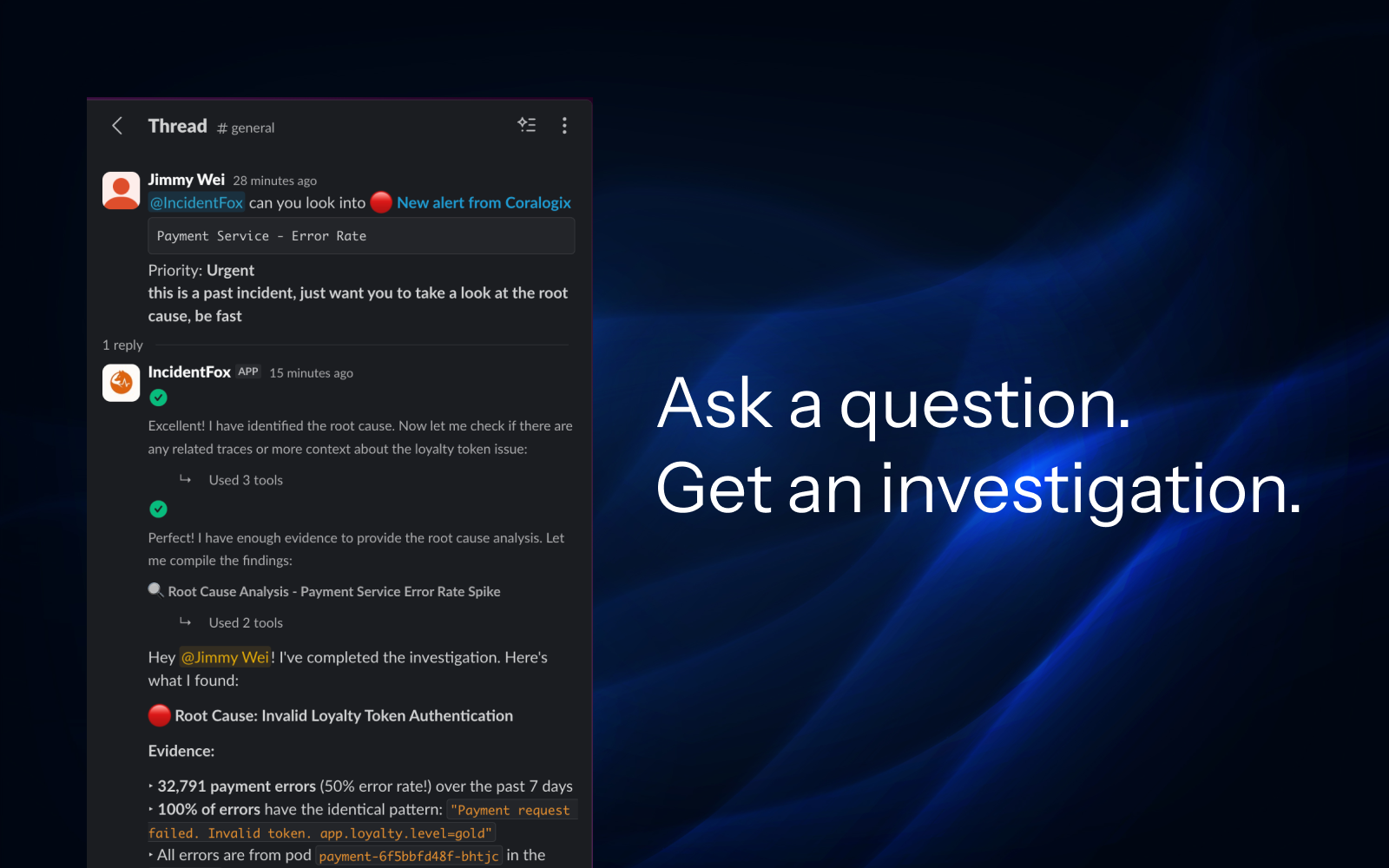
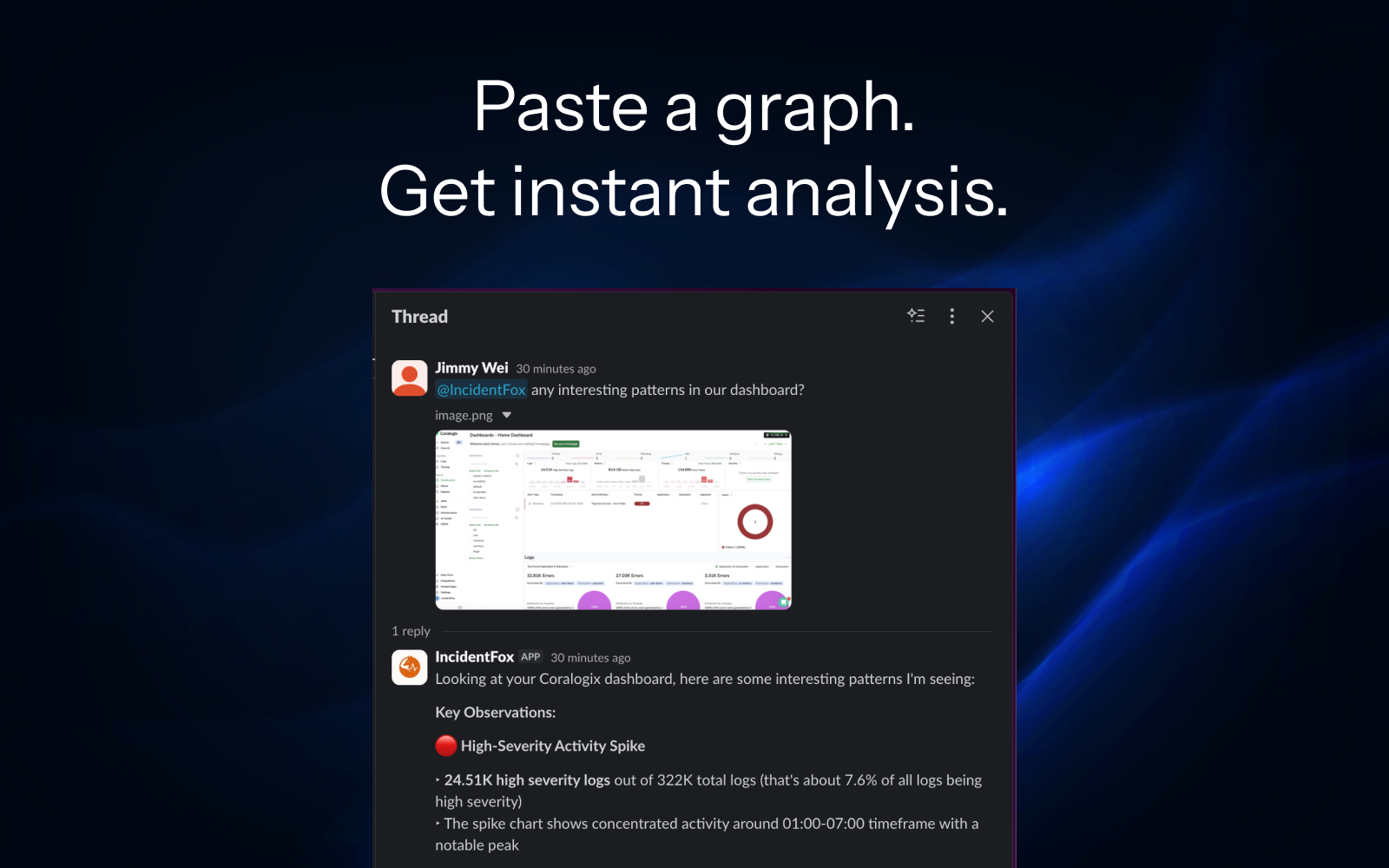
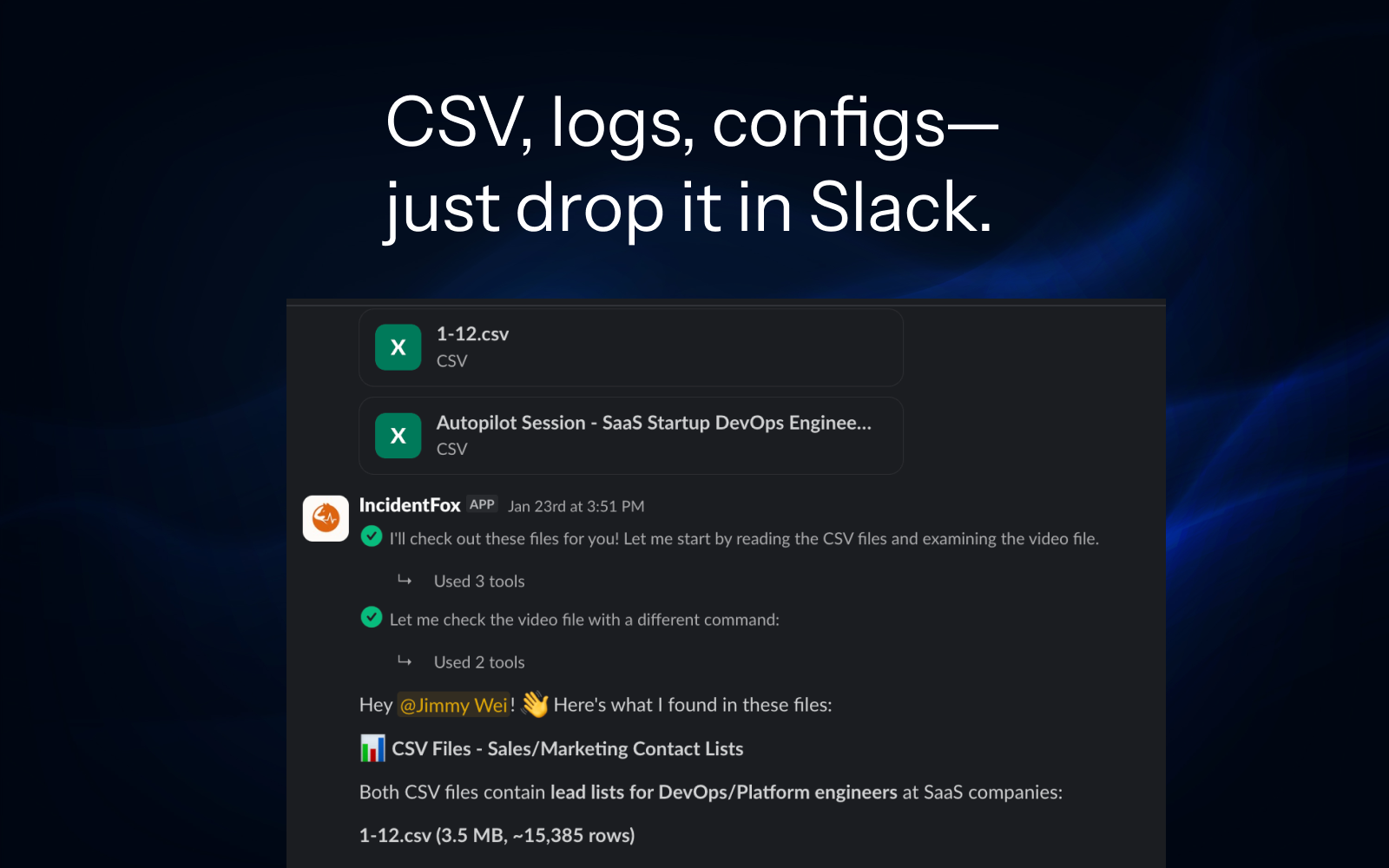
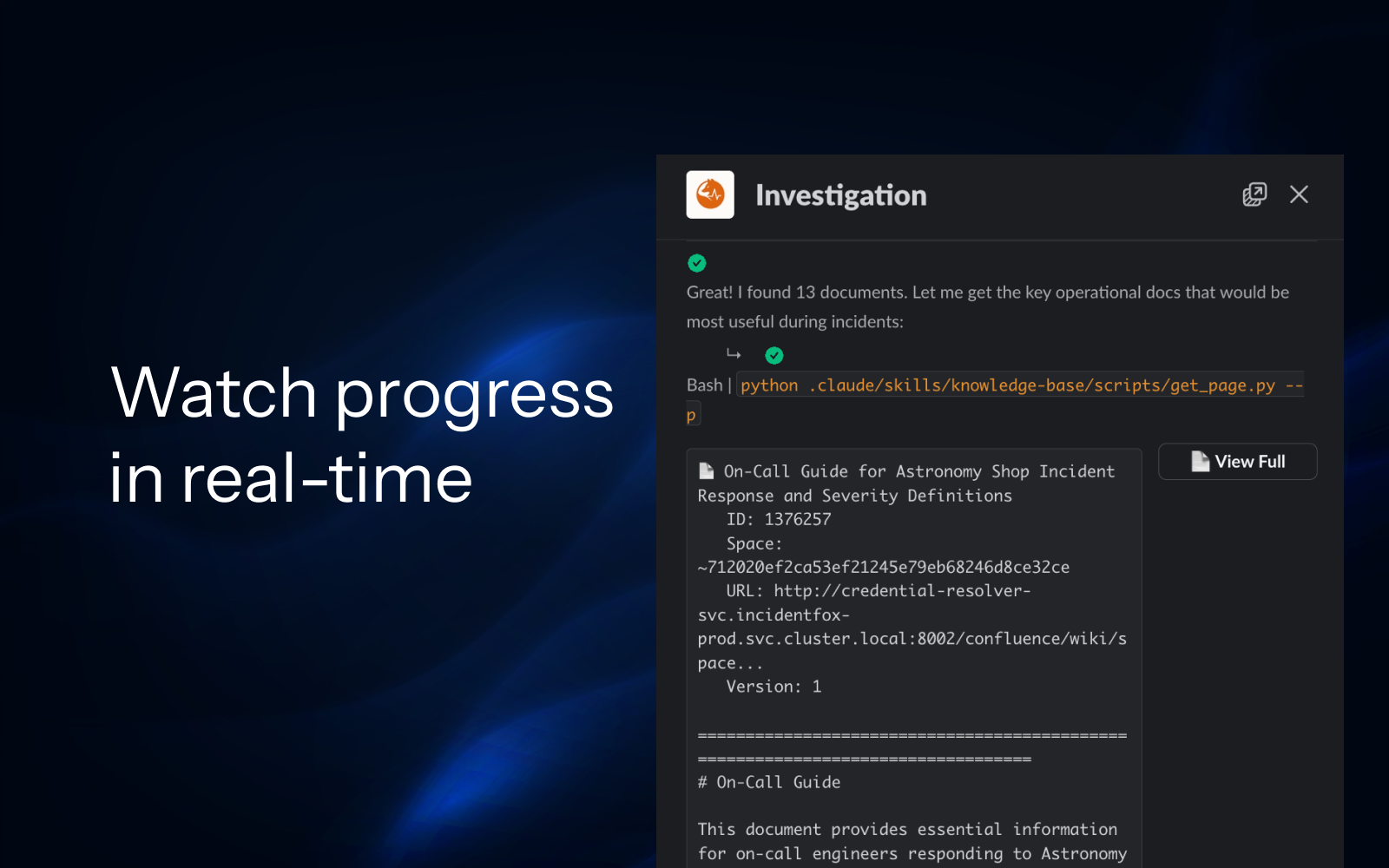
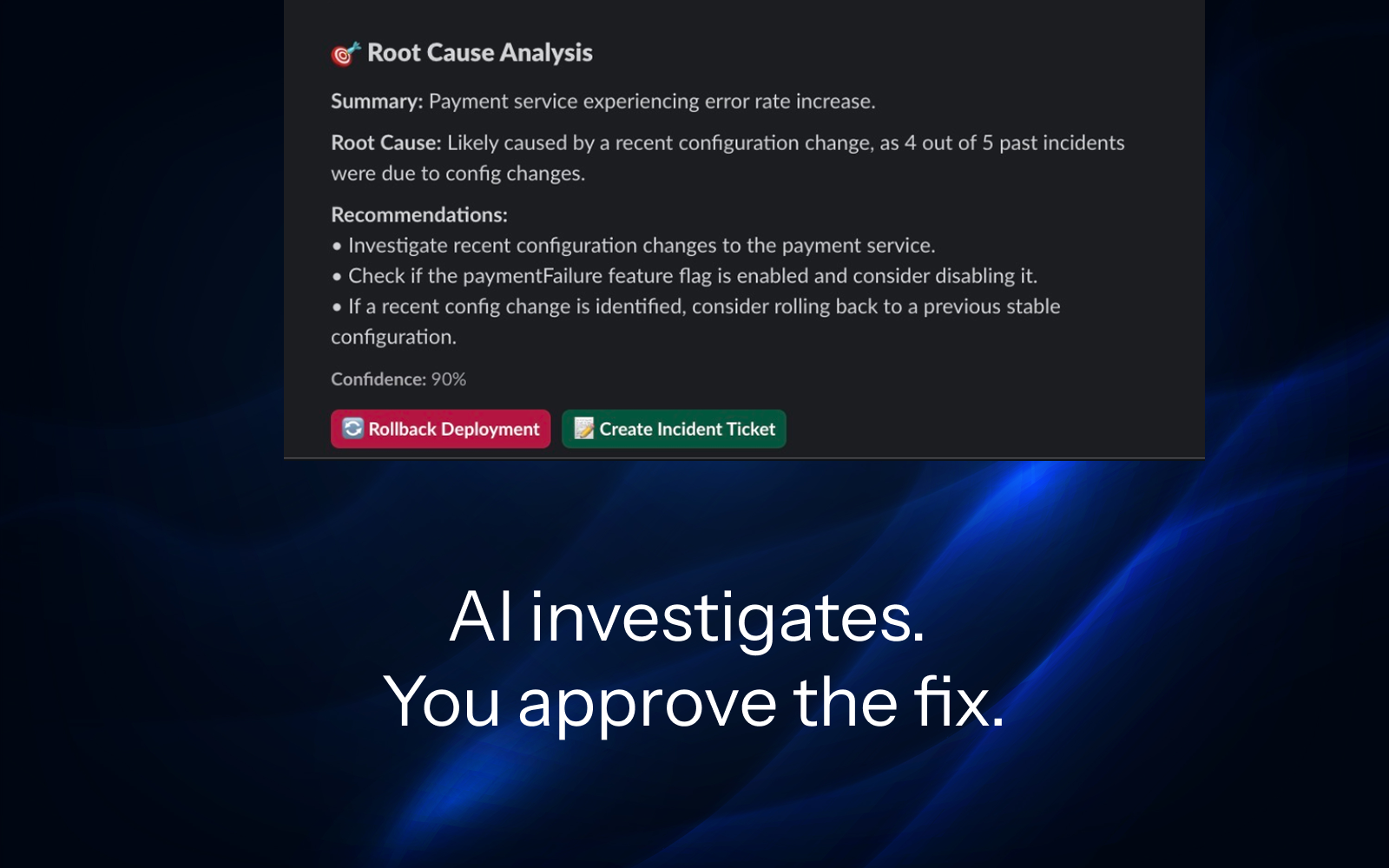
AI Incident Investigator
That Debugs While You Sleep.
We analyze your codebase and past incidents to understand your stack, then auto-build the integrations. By the time you wake up, you have root cause + fix scripts. Just review and approve.
Auto-learns your stack
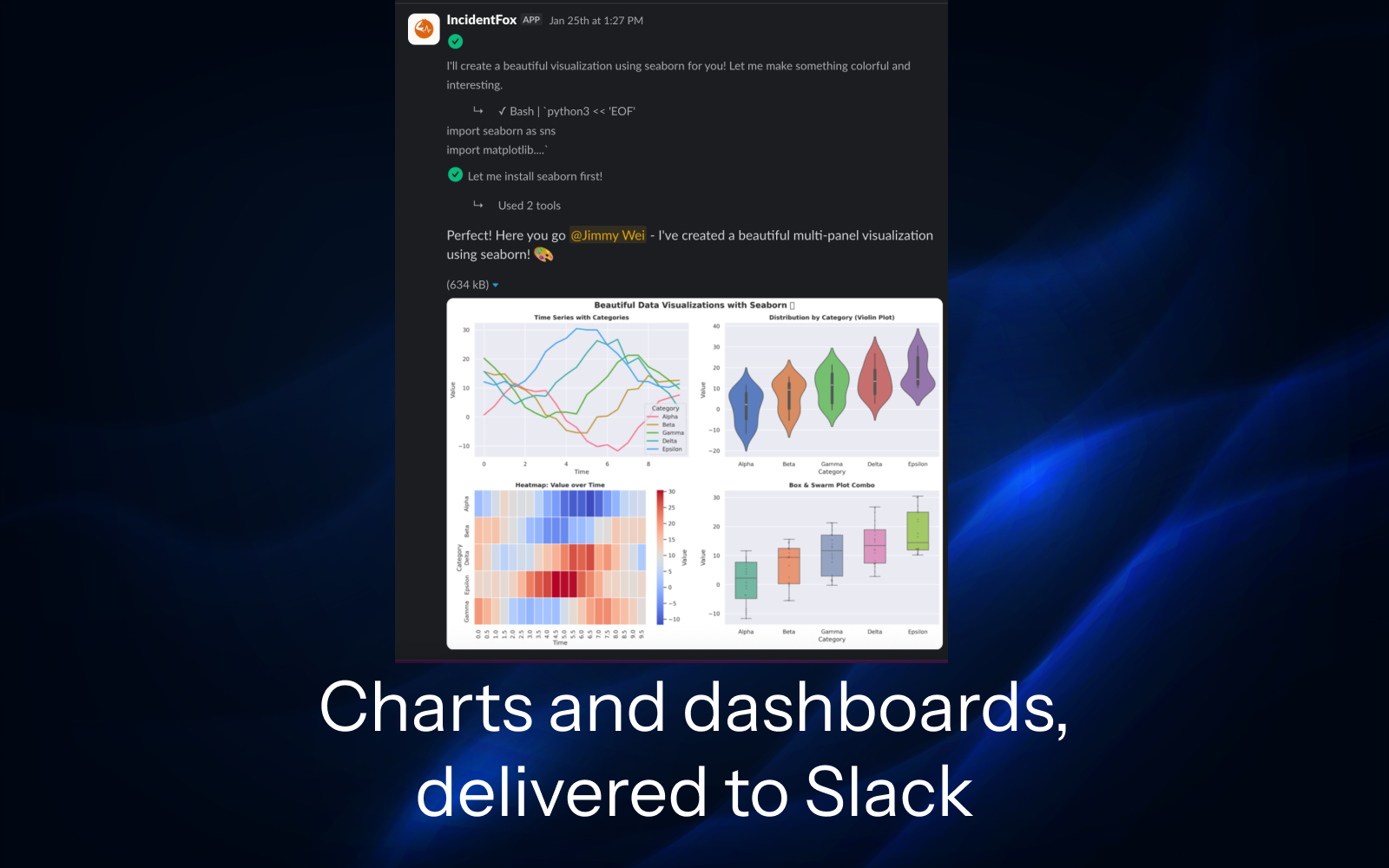
Everything in Slack
No setup required to try
Backed By
 Combinator
W26
Combinator
W26
Combinator
W26
Slack
PagerDuty
AWS
Datadog
Prometheus
Grafana
GitHub
Coralogix
Kubernetes
Elasticsearch
Splunk
Sentry
Jira
Linear
GitLab
OpsGenie
New Relic
PostgreSQL
MySQL
Confluence
Slack
PagerDuty
AWS
Datadog
Prometheus
Grafana
GitHub
Coralogix
Kubernetes
Elasticsearch
Splunk
Sentry
Jira
Linear
GitLab
OpsGenie
New Relic
PostgreSQL
MySQL
Confluence
Works with 40+ integrations